大多数的救火车都是红色的,但是用蓝色描绘一个并不难。电脑几乎没有创造力。
他们对世界的理解通常会从字面上被他们所训练的数据所着色。如果他们所看到的只是红色消防车的照片,他们将无法绘制其他任何东西。
为了给计算机视觉模型一个更完整,更富想象力的世界视图,研究人员试图为它们提供更多不同的图像。有些人尝试从奇特的角度和不寻常的位置拍摄物体,以更好地传达其真实世界的复杂性。其他人则要求模型使用称为GAN或生成对抗网络的人工智能形式生成自己的图片。在这两种情况下,目的都是为了填补图像数据集的空白,以更好地反映三维世界,并减少面部和物体识别模型的偏倚。
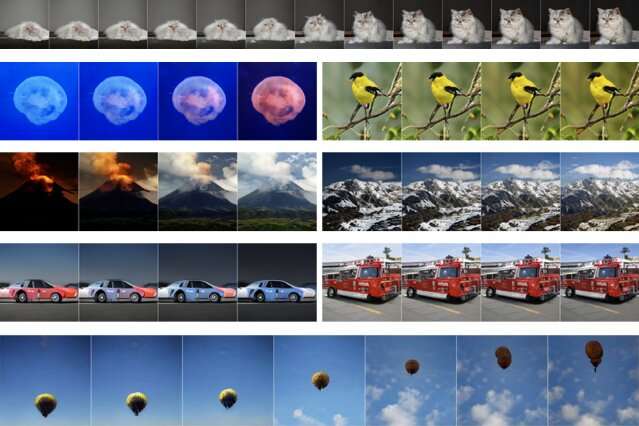
在国际学习表示会议上的一项新研究中,麻省理工学院的研究人员提出了一种创造力测试,以了解GAN可以对给定图像进行细化处理。他们将模型 “引导” 到照片的主体中,并要求其在明亮的光线下,在空间中旋转或以不同的颜色绘制特写的物体和动物。
该模型的创建方式有些微妙,有时甚至令人惊讶。事实证明,这些变化紧密地追踪了人类摄影师如何在镜头前构图场景。这些偏见被烘焙到基础数据集中,并且该研究中提出的控制方法旨在使这些限制显而易见。
麻省理工学院的研究科学家阿里·贾哈尼安说:“潜伏空间是图像的DNA所在。” “我们证明,您可以直接进入这个抽象空间,并控制您希望GAN表现出的特性,直到某一点。我们发现GAN的创造力受到其学习图像多样性的限制。” 贾哈尼(Jahanian)是该研究的合著者卢西·柴(Lucy Chai)参与的研究。麻省理工学院的学生,高级作者Phillip Isola,Bonnie and Marty(1964)Tenenbaum CD电气工程和计算机科学助理教授。
研究人员将他们的方法应用于已经接受ImageNet 1400万张照片训练的GAN。然后,他们测量了模型在变换不同类别的动物,物体和场景方面可以走多远。他们发现,艺术冒险的程度因GAN试图操纵的主题类型而异。
例如,一个上升的热气球比旋转的比萨饼产生更多的醒目的姿势。放大波斯猫而不是知更鸟时,情况也是如此,猫离观察者越远,它们融化成一堆毛皮,而鸟几乎保持不变。他们发现,模特高兴地把汽车变成了蓝色,将水母变成了红色,但是它拒绝用标准颜色以外的任何颜色画金翅雀或救火车。
GAN似乎还令人惊讶地适应了某些景观。当研究人员提高一组山上照片的亮度时,该模型异想天开地向火山中喷出了火热喷发,但在阿尔卑斯山却没有一个地质上较老的休眠亲戚。好像GAN捕捉到的GAN会随着白天到深夜的变化而变化,但似乎可以理解,只有火山在晚上变得更亮。
研究人员说,这项研究提醒人们,深度学习模型的输出在多大程度上取决于其数据输入。GAN凭借其从数据推断和以新颖的方式可视化世界的能力而引起了情报研究人员的关注。
他们可以拍摄爆头,然后将其转换成文艺复兴时期风格的肖像或喜爱的名人。但是,尽管GAN能够自己学习令人惊讶的细节,例如如何将风景分为云朵和树木,或生成贴在人们脑海中的图像,但它们仍然主要是数据的奴隶。他们的创作反映了成千上万摄影师的偏见,无论是他们选择的拍摄方式还是构图的方式。
芬兰Aaalto大学教授,NVIDIA研究科学家Jaako Lehtinen表示:“我喜欢这项工作,是在看GAN所学到的陈述,并推动它揭示做出这些决定的原因。”研究。“ GAN令人难以置信,可以学习有关物理世界的各种事物,但是它们仍然无法像人类一样以物理上有意义的方式表示图像。”