那些从事机器学习(ML)项目的人都知道ML需要大量数据来训练所得算法。有人会说您永远不会拥有太多数据。数据量和生成的ML模型的复杂程度之间通常存在相关性。随着AI向新的利益池发展,同时利用更复杂的AI功能,这种数据饥渴只会变得更加强烈。由于人工智能的复杂性还存在其他促成的趋势,因此组织面临的问题是:“他们是否拥有正确的数据来推动成功的AI工作?” 如果他们没有足够的资源,他们是否应该在期待AI盛宴的情况下库存更多?
组织收集的所有大数据不可能都是正确的数据,但是了解AI的去向将使组织在AI的发展和未来几十年的收集和收集更多正确数据方面具有“立足点”。
人工智能的进步改变了数据游戏
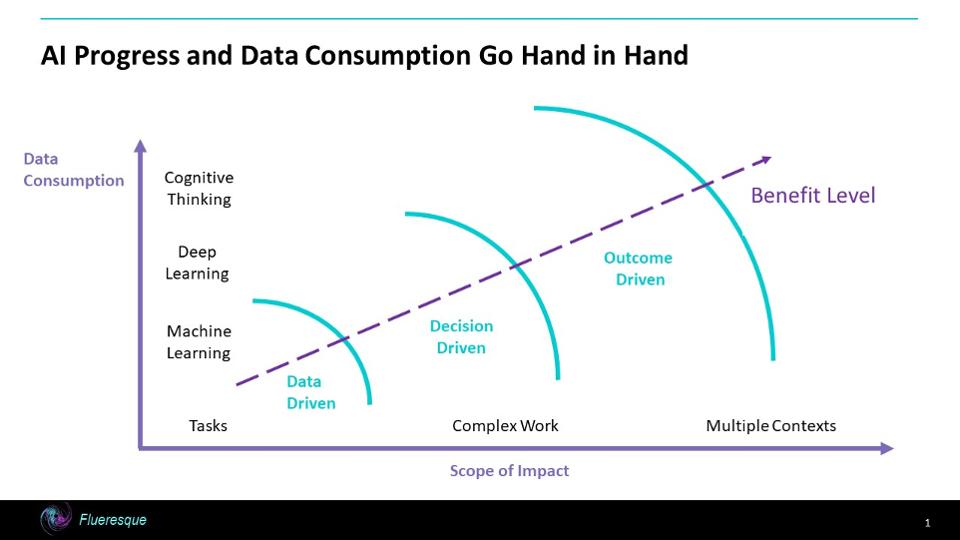
虽然ML需要大量数据来自我修改其行为,但随着AI功能复杂性的提高,AI的需求也迅速增加。从机器学习到深度学习(DL)迈出了一大步,因为DL比ML需要更多的数据。原因是DL通常只能识别神经网络各层之间的概念差异。当暴露给数百万个数据点时,DL确定概念的边缘。DL允许机器像人的大脑一样通过神经网络来表示概念,从而可以解决更复杂的问题。人工智能还可以解决答案更加不确定或模棱两可的模糊问题。这些通常是判断或识别问题,可以扩展到创作或其他右脑活动。这又需要更多数据,
从数据驱动到结果驱动的转变
随着AI在其协助或解决的复杂问题中不断发展,它将成为数据驱动和目标/结果驱动的。这意味着AI可能会即时请求解决特定问题或进行特定推论所需的数据,从而使数据管理变得复杂。它可能涉及解决方案的归纳数据驱动部分与基于达到目标的假设的数据演绎需求的交互。对于面向结果的问题,需要进行这种动态交互。这与仅查询数据以寻找有趣的事件和模式有很大不同。决策驱动方法恰好适合这两种截然不同的方法。通过将数据与结果进行匹配,一些决策将集中在运营上并加以改进。在归纳法和演绎法上都会有更多的战略决策。这只是增加数据使用量的另一个需求渠道。
不断变化的问题范围影响数据需求
AI解决方案的范围通常会从狭窄的领域开始,并随着时间的流逝而扩大到更大的范围,因此需要更多数据。复杂解决方案通常针对多个答案,并且需要更多数据来支持支路解决方案集,从而导致复杂/混合结果。随着决策,行动和结果的范围跨越组织内部和外部的更多上下文,将需要获取更多数据以了解每种上下文及其相互作用。这些上下文中的每一个都可能以不同的速率变化和变形,因此,需要更多的数据。
净; 净:
显然,更多数据将成为AI辅助解决方案的标志。数据需求可能来自更具挑战性的问题,高级AI /分析的更好利用或端到端价值链的增长。有一件事情是肯定的。组织最好为“ AI /数据交互”的新世界做好准备。它可以更改或扩展数据管理策略,方法,技术或技术。请参阅图1,以查看交互可能性。