NVIDIA刚刚发布了其Ampere A100 GPU的第一个实际性能数据,结果令人疯狂。该公司在AI特定基准测试中总共打破了16条性能记录,并且在特定的机器学习性能类别中击败了其主要竞争对手,取得了巨大的领先优势。

结果来自MLPerf.MLPerf是一家成立于2018年的行业基准测试组,主要专注于机器学习性能。该基准套件包括总共八项测试,并且NVIDIA已以创纪录的培训速度发布了所有记录。
这是NVIDIA在2018年5月成立的行业基准测试组织MLPerf进行的培训测试中连续第三次,也是最强劲的表现。NVIDIA在2018年12月的首个MLPerf培训基准中创下了六项记录,在2019年7月创下了八项记录。
NVIDIA是唯一一家为所有测试提供商用产品的公司。大多数其他提交使用的预览类别是可能几个月不可用的产品,而研究类别是使用预期时间不会可用的产品的。
NVIDIA博客
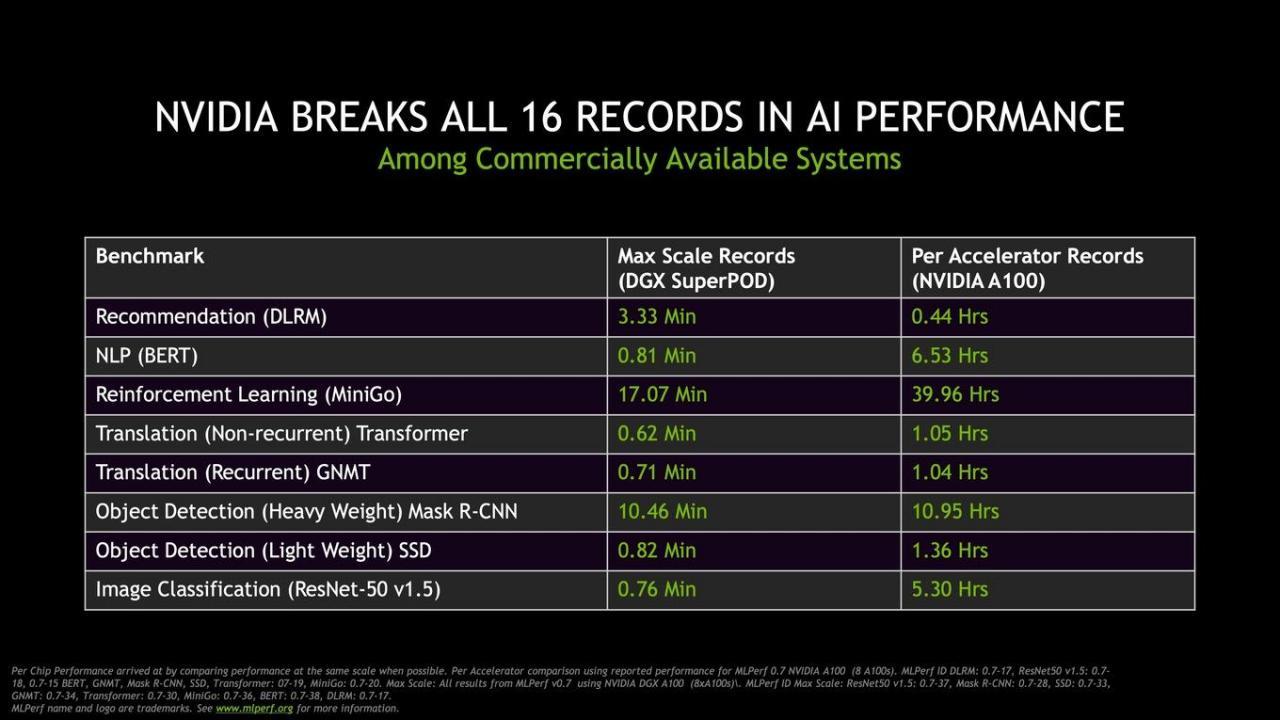
NVIDIA还报告了其DGX SuperPOD系统的八项新记录,该系统是通过HDR InfiniBand连接在一起的庞大的DGX A100 HPC系统集群。DGX SuperPod由140个DGX A100系统组成,总共有1,120个NVIDIA Ampere A100 GPU,170个Mellanox Quantum 200G Infiniband交换机,4 PB的存储空间和15公里的光缆。
令人赞叹的DGX SuperPod系统中大约有770万个Ampere CUDA内核。该系统是DGX V扩展计划的一部分,为该系统增加了近700 Petaflops的计算能力,该系统目前已部署在加利福尼亚州圣克拉拉市的NVIDIA总部。
人工智能性能基准-安培vs伏特&更多
NVIDIA已将其Ampere A100 Tensor Core GPU加速器与其前身Volta V100进行了比较。比较还包括Google的第三代TPU和华为的Ascend HPC芯片。MLPerf本身列出了更详细的基准测试,还预览了即将推出的AI加速器,例如英特尔的Cooper Lake-SP Xeon CPU和Google的第四代TPU。话虽如此,让我们看一下基准测试本身。
根据MLPerf的说法,他们的基准套件包括针对机器学习和AI类别中最相关的性能工作负载的测试。NVIDIA Ampere A100只是将Volta V100毁坏,而性能却提高了2.5倍。即使以最低的领先优势,Ampele A100仍比Volta V100 GPU提升了50%,令人印象深刻。此处的芯片规模已标准化为单个GPU,以便在Ampere和Volta之间进行合理的比较。
华为Ascend芯片只能及时完成一项测试,而且性能也比Volta V100差,而Google的TPU V3只能及时完成两项测试。在一项测试中,该芯片比NVIDIA Volta V100领先20%,而在第二项测试中,它比V100慢10%。
与Cooper Lake-SP 8插槽配置可在1104.53分钟内完成图像分类测试相比,双NVIDIA A100系统仅需33.37分钟即可完成同一测试。NVIDIA还继续将其Ampere A100的性能与尚未发布的Google TPU V4进行比较,Google TPU V4仍处于研究阶段,并且距离上市至少一年。
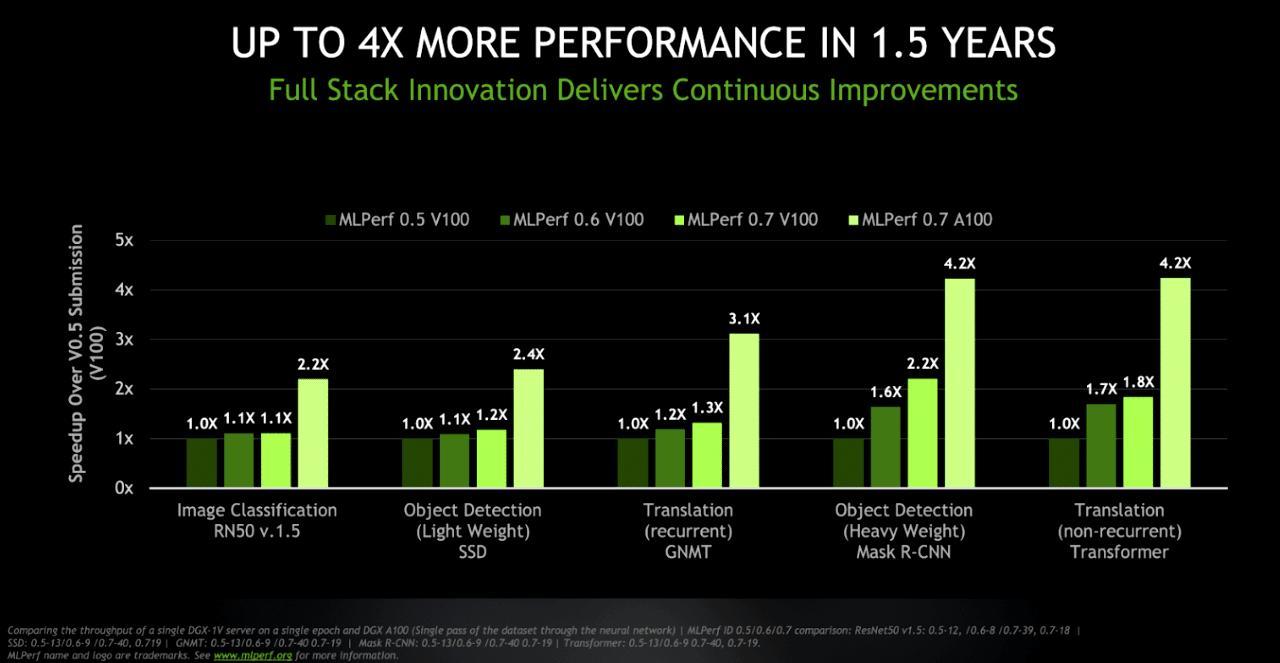
NVIDIA还展示了其GPU加速器的性能如何随着AI的最新全栈创新而不断提高。与在Volta V100上运行的MLPerf 0.5相比,与Ampere A100一起运行的MLPerf 0.7套件提供了惊人的4.2倍性能提升。
这证明了NVIDIA Ampere A100 GPU的芯片在AI社区中所有主要玩家认可的套件中的真实基准中的表现令人印象深刻。即使与Turing GPU相比,Ampele A100 GPU也被认为是另一个基准测试中最快的GPU,图灵GPU的硬件加速技术能够提供更好的性能,但仍然无法与Ampere A100及其强大的性能输出相提并论。所有这些基准功能使我们更加高兴地看到以消费者形式的安培,这肯定会在几个月后发生。







