谷歌去年6月宣布将Cloud Dataflow作为一项托管服务,旨在帮助公司以批处理和实时流模式提取和分析海量数据集。去年12月,该公司向开源社区发布了Cloud Dataflow软件开发套件,以鼓励软件开发人员编写易于与托管服务以及其他执行环境集成的应用程序。
这一举措的结果之一是在Cloudera的开源Apache Spark引擎发行版上运行的Cloud Dataflow版本,用于大规模数据处理。Cloudera和Google于1月20日宣布了新的Dataflow“运行程序” ,开发人员将可以将Dataflow管道作为目标,以便在云托管或本地Spark集群以及Google托管服务上执行。
Cloud Dataflow最引人注目的方面之一是它对可以同时执行批处理和流模式的流水线逻辑的支持,Cloudera数据科学高级总监Josh Wills在该公司的博客中宣布了这一新发展。
Wills说,Cloud Dataflow的流传输功能比Spark Streaming所提供的先进,而其批处理执行引擎可优化不处理流数据的管道的性能。
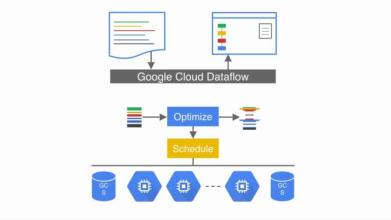
Cloud Dataflow结合了Google多年来在内部用于大型数据处理的几种主要技术,包括MapReduce,FlumeJava批处理引擎和MillWheel流处理引擎。谷歌云平台团队的产品经理埃里克·施密特(Eric Schmidt)说:“数据流是我们对数据处理技术的综合投资。” 他说:“从开发人员的角度来看,它是一种编程模型和一种托管服务。”
Google去年12月发布的Cloud Dataflow SDK为开发人员提供了一种编写结合了批处理和流处理功能的大数据应用程序的方式,而无需使用单独的编程模型或单独的基础结构来运行它们。
施密特说:“他们以前必须做的是运行一个不同的SDK。” 他说:“您要么让一组用户执行静态的MapReduce批处理作业,要么就拥有另一个阵营[进行流分析]。” 他说:“我们希望将批处理和流合并,并拥有一个组合的服务基础架构”,以同时运行这两种服务。
他说,Google于12月将SDK发布到开源社区,以确保将Dataflow也移植到其他执行环境。他说,Cloudera Apache Spark的发布是Google考虑到Dataflow方向的一个例子。
Google首次宣布Dataflow时的关键问题之一是,使用该编程模型的开发人员是否会被锁定在Google基础架构中以运行其管道。施密特说:“我们的策略是将SDK扩展到开源,以便他们可以将其扩展到其他环境。”
他说,随着周二的宣布,Cloud Dataflow现在可以在Google的基础架构,Spark集群或本地计算机上运行。
Google的举动旨在更好地将公司定位于服务和技术的新兴市场,以帮助企业从海量数据集中提取业务价值。多年来,许多公司在从事务处理系统,点击流,系统日志,机器传感器,移动设备和其他来源中收集各种数据方面已经做得更好。但是,由于传统数据库管理技术的局限性以及为大数据集构建数据处理基础架构所涉及的复杂性,他们一直在努力从中获取价值。