Demis Hassabis创立了DeepMind的目标是通过重新创建情报本身来解锁一些世界上最棘手的问题的答案。他的野心仍然只是雄心勃勃,但是哈萨比斯和他的同事们在本周实现这一目标的步伐越来越近,在《自然 》杂志上发表了论文,解决了生物医学面临的两个巨大挑战。

第一篇论文起源于DeepMind的神经科学团队,提出了AI研究的发展可以作为理解大脑如何学习的框架的观点。另一篇论文侧重于DeepMind在蛋白质折叠方面的工作-该工作于2018年12月进行了详细介绍。这两篇论文均紧随DeepMind在将AI用于预测急性肾损伤或AKI以及挑战性游戏环境等方面的工作之后。进行围棋,将棋,象棋,数十种Atari游戏以及Activision Blizzard的StarCraft II。
哈萨比斯说:“很高兴看到我们在[机器学习]中的研究如何指向对大脑中起作用的学习机制的新理解。” “ [另外,了解]蛋白质如何折叠是一个长期存在的基本科学问题,有朝一日可能成为解锁针对各种疾病的新疗法的关键,从阿尔茨海默氏症和帕金森氏症到囊性纤维化和亨廷顿氏症,人们都认为错折叠的蛋白质会扮演一个角色。”
在有关多巴胺的论文中,来自DeepMind和哈佛大学的团队研究了大脑是否代表了未来可能的回报,而不是作为一个单一的平均值,而是作为一个概率分布,该数学函数提供了发生不同结果的可能性。他们从小鼠腹侧被盖区域(控制多巴胺向边缘和皮质区域释放的中脑结构)的录音中发现了“ 分布强化学习 ”的证据。有证据表明,奖励预测是同时并行地由多个未来结果表示的。

人工智能系统模仿人类生物学的想法并不新鲜。荷兰拉德布德大学研究人员进行的一项研究发现,递归神经网络(RNN)可以预测人脑如何处理感官信息,特别是视觉刺激。但是,在大多数情况下,这些发现为机器学习提供了信息,而不是神经科学研究。
2017年,DeepMind通过模仿前额叶皮层行为的AI算法和发挥海马作用的“记忆”网络构建了人脑的解剖模型,从而使该系统的性能大大优于大多数机器学习模型架构。最近,DeepMind将注意力转向了理性机器,产生了能够将类人推理能力和逻辑应用于解决问题的合成神经网络。在2018年,DeepMind的研究人员进行了一项实验,表明前额叶皮层并不像过去那样依赖突触权重变化来学习规则结构,而是使用直接在多巴胺中编码的基于抽象模型的信息。
强化学习涉及仅使用奖励和惩罚作为教学信号来学习行为的算法。奖励或多或少地增强了导致其获得的任何行为。
正如研究人员指出的那样,解决问题需要了解当前的行动如何带来未来的回报。这就是时差学习(TD)算法出现的地方-他们试图预测即时奖励以及在下一个时刻自己的奖励预测。当这带来更多信息时,算法会将新的预测与预期的进行比较。如果两者不同,则使用此“时间差异”将旧的预测调整为新的预测,以使链条变得更加准确。
强化学习技术已随着时间的流逝而得到改进,以提高培训的效率,最近开发的一种技术称为
由特定动作产生的未来奖励的数量通常不是已知数量,而是涉及一些随机性。在这种情况下,标准的TD算法会学会预测平均会收到的未来奖励,而分布式强化算法会预测整个奖励范围。
这与动物大脑中多巴胺神经元的功能无异。一些神经元表示奖励预测错误,这意味着它们在收到比预期更多或更少的奖励时会触发(即发送电信号)。这就是所谓的奖励预测误差理论-计算奖励预测误差,通过多巴胺信号将其传播到大脑,并用于驱动学习。
分布强化学习扩展了多巴胺的典范奖励预测误差理论。以前曾有人认为,奖励预测仅表示为一个数量,支持对随机(即,随机确定)结果的平均值(或平均值)的了解,但是这项工作表明大脑实际上考虑了多种预测。DeepMind研究科学家Zeb Kurth-Nelson说:“在大脑中,强化学习是由多巴胺驱动的。” “我们在……论文中发现,每个多巴胺细胞都经过了特殊的调整,可以使细胞群以前所未有的方式非常有效地重新布线这些神经网络。”
最简单的分布增强算法之一-分布TD-假定基于奖励的学习受奖励预测错误驱动,该错误会发出已接收到的奖励和预期奖励之间的差异。但是,与传统的强化学习相反,在这种预测中,预测被表示为一个单一的数量(即所有潜在结果的平均值,以其概率加权),而分布强化则使用了几种预测,这些预测对即将来临的奖励的乐观程度各不相同。
分布式TD算法通过计算描述连续预测之间差异的预测误差来学习这组预测。内部的一组预测变量将不同的变换应用于其各自的奖励预测错误,从而使某些预测变量有选择地“放大”或“超重”其奖励错误。当奖励预测误差为正时,某些预测器会学习到对应于分布的较高部分的更乐观的奖励,而当奖励预测为负时,他们将学习更多的悲观预测。这就导致了悲观或乐观价值估计的多样性,这些估计捕获了奖励的全部分配。
“在过去的三十年中,我们在AI中最好的强化学习模型…几乎完全专注于学习以预测未来的平均回报。但这并不能反映现实生活。” DeepMind研究科学家Will Dabney说。“ [实际上有可能]时刻预测奖励成果的整个分布。”
分布式强化学习的执行很简单,但是与机器学习系统一起使用时非常有效-它可以将性能提高两倍或更多。那可能是因为了解奖励的分配会给系统提供一个更强大的信号,以塑造其表
分布式学习与多巴胺
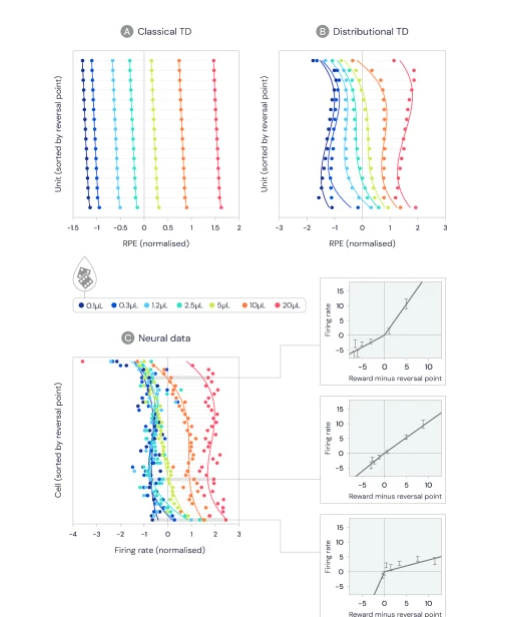
然后,该研究试图确定大脑是否使用某种形式的分布TD。研究小组分析了11只小鼠在执行刺激任务时制作的多巴胺细胞的记录。五只老鼠接受了概率可变的任务训练,而六只接受了幅度可变的任务的训练。第一组暴露于四种随机气味中的一种,然后喷水,吹气或什么也没有。(第一种气味表示获得奖励的机会为90%,第二种,第三种和第四种气味表示获得奖励的机会分别为50%,10%和90%。)
多巴胺细胞改变发射速率以指示预测误差,这意味着当收到的奖励恰好是细胞预测的确切大小时,预测误差应该为零。考虑到这一点,研究人员确定了每个细胞的反转点-多巴胺细胞不会改变其发射速率的奖励大小-并比较了它们是否存在差异。
他们发现,某些单元格预测了大量的奖励,而另一些单元格则预测了很少的奖励,远远超出了可变性可能带来的差异。他们在测量了不同细胞展现出阳性预期和阴性预期的扩增程度之后,再次看到了多样性。他们观察到,放大其阳性预测误差的相同细胞具有更高的逆转点,表明它们已被调整以期望更高的奖励量。
在最后的实验中,研究人员试图从多巴胺细胞的发射速率中解码奖励分布。他们报告了成功:通过推理,他们设法重建了与老鼠从事的任务中的实际奖励分配相匹配的分配。
“在研究来自AI的思想的过程中,很容易将注意力集中在从AI到神经科学的思想流中。但是,我们认为结果对于AI同样重要。” DeepMind神经科学研究主任Matt Botvinick说。“当我们能够证明大脑采用了我们在AI工作中所使用的算法时,就增强了我们的信心,即这些算法从长远来看将是有用的-它们可以很好地扩展到复杂的现实世界中,与其他计算过程的接口很好。其中涉及一种验证:如果大脑正在做,那可能是个好主意。”
蛋白质折叠
两篇论文的第二篇详细介绍了DeepMind在蛋白质折叠领域的工作,这项工作始于两年前。正如研究人员所指出的那样,预测蛋白质形状的能力是了解蛋白质如何在体内发挥作用的基础。这不仅对健康有影响,而且可以帮助应对许多社会挑战,例如管理污染物和减少废物。
蛋白质的配方(由氨基酸组成的大分子组成,氨基酸是组织,肌肉,头发,酶,抗体和其他生物的基本组成部分的基本组成部分)在DNA中编码。这些遗传定义界定了它们的三维结构,从而决定了它们的功能。例如,抗体蛋白质的形状像“ Y”形,使它们能够锁定在病毒和细菌上,而胶原蛋白的形状像绳索,在软骨,骨骼,皮肤和韧带之间传递张力。
Demis Hassabis创立了DeepMind的目标是通过重新创建情报本身来解锁一些世界上最棘手的问题的答案。他的野心仍然只是雄心勃勃,但是哈萨比斯和他的同事们在本周实现这一目标的步伐越来越近,在《自然 》杂志上发表了论文,解决了生物医学面临的两个巨大挑战。
第一篇论文起源于DeepMind的神经科学团队,提出了AI研究的发展可以作为理解大脑如何学习的框架的观点。另一篇论文侧重于DeepMind在蛋白质折叠方面的工作-该工作于2018年12月进行了详细介绍。这两篇论文均紧随DeepMind在将AI用于预测急性肾损伤或AKI以及挑战性游戏环境等方面的工作之后。进行围棋,将棋,象棋,数十种Atari游戏以及Activision Blizzard的StarCraft II。
哈萨比斯说:“很高兴看到我们在[机器学习]中的研究如何指向对大脑中起作用的学习机制的新理解。” “ [另外,了解]蛋白质如何折叠是一个长期存在的基本科学问题,有朝一日可能成为解锁针对各种疾病的新疗法的关键,从阿尔茨海默氏症和帕金森氏症到囊性纤维化和亨廷顿氏症,人们都认为错折叠的蛋白质会扮演一个角色。”
在有关多巴胺的论文中,来自DeepMind和哈佛大学的团队研究了大脑是否代表了未来可能的回报,而不是作为一个单一的平均值,而是作为一个概率分布,该数学函数提供了发生不同结果的可能性。他们从小鼠腹侧被盖区域(控制多巴胺向边缘和皮质区域释放的中脑结构)的录音中发现了“ 分布强化学习 ”的证据。有证据表明,奖励预测是同时并行地由多个未来结果表示的。
人工智能系统模仿人类生物学的想法并不新鲜。荷兰拉德布德大学研究人员进行的一项研究发现,递归神经网络(RNN)可以预测人脑如何处理感官信息,特别是视觉刺激。但是,在大多数情况下,这些发现为机器学习提供了信息,而不是神经科学研究。
2017年,DeepMind通过模仿前额叶皮层行为的AI算法和发挥海马作用的“记忆”网络构建了人脑的解剖模型,从而使该系统的性能大大优于大多数机器学习模型架构。最近,DeepMind将注意力转向了理性机器,产生了能够将类人推理能力和逻辑应用于解决问题的合成神经网络。在2018年,DeepMind的研究人员进行了一项实验,表明前额叶皮层并不像过去那样依赖突触权重变化来学习规则结构,而是使用直接在多巴胺中编码的基于抽象模型的信息。
强化学习与神经元
强化学习涉及仅使用奖励和惩罚作为教学信号来学习行为的算法。奖励或多或少地增强了导致其获得的任何行为。
正如研究人员指出的那样,解决问题需要了解当前的行动如何带来未来的回报。这就是时差学习(TD)算法出现的地方-他们试图预测即时奖励以及在下一个时刻自己的奖励预测。当这带来更多信息时,算法会将新的预测与预期的进行比较。如果两者不同,则使用此“时间差异”将旧的预测调整为新的预测,以使链条变得更加准确。
强化学习技术已随着时间的流逝而得到改进,以提高培训的效率,最近开发的一种技术称为分布式强化学习。
分布强化学习
由特定动作产生的未来奖励的数量通常不是已知数量,而是涉及一些随机性。在这种情况下,标准的TD算法会学会预测平均会收到的未来奖励,而分布式强化算法会预测整个奖励范围。
这与动物大脑中多巴胺神经元的功能无异。一些神经元表示奖励预测错误,这意味着它们在收到比预期更多或更少的奖励时会触发(即发送电信号)。这就是所谓的奖励预测误差理论-计算奖励预测误差,通过多巴胺信号将其传播到大脑,并用于驱动学习。
分布强化学习扩展了多巴胺的典范奖励预测误差理论。以前曾有人认为,奖励预测仅表示为一个数量,支持对随机(即,随机确定)结果的平均值(或平均值)的了解,但是这项工作表明大脑实际上考虑了多种预测。DeepMind研究科学家Zeb Kurth-Nelson说:“在大脑中,强化学习是由多巴胺驱动的。” “我们在……论文中发现,每个多巴胺细胞都经过了特殊的调整,可以使细胞群以前所未有的方式非常有效地重新布线这些神经网络。”
最简单的分布增强算法之一-分布TD-假定基于奖励的学习受奖励预测错误驱动,该错误会发出已接收到的奖励和预期奖励之间的差异。但是,与传统的强化学习相反,在这种预测中,预测被表示为一个单一的数量(即所有潜在结果的平均值,以其概率加权),而分布强化则使用了几种预测,这些预测对即将来临的奖励的乐观程度各不相同。
分布式TD算法通过计算描述连续预测之间差异的预测误差来学习这组预测。内部的一组预测变量将不同的变换应用于其各自的奖励预测错误,从而使某些预测变量有选择地“放大”或“超重”其奖励错误。当奖励预测误差为正时,某些预测器会学习到对应于分布的较高部分的更乐观的奖励,而当奖励预测为负时,他们将学习更多的悲观预测。这就导致了悲观或乐观价值估计的多样性,这些估计捕获了奖励的全部分配。
我们可以根据其发射率来解码奖励的分布。灰色阴影区域是任务中遇到的奖励的真实分布。
“在过去的三十年中,我们在AI中最好的强化学习模型…几乎完全专注于学习以预测未来的平均回报。但这并不能反映现实生活。” DeepMind研究科学家Will Dabney说。“ [实际上有可能]时刻预测奖励成果的整个分布。”
分布式强化学习的执行很简单,但是与机器学习系统一起使用时非常有效-它可以将性能提高两倍或更多。那可能是因为了解奖励的分配会给系统提供一个更强大的信号,以塑造其表示形式,使其对环境或给定政策的变化更加稳健。
分布式学习与多巴胺
然后,该研究试图确定大脑是否使用某种形式的分布TD。研究小组分析了11只小鼠在执行刺激任务时制作的多巴胺细胞的记录。五只老鼠接受了概率可变的任务训练,而六只接受了幅度可变的任务的训练。第一组暴露于四种随机气味中的一种,然后喷水,吹气或什么也没有。(第一种气味表示获得奖励的机会为90%,第二种,第三种和第四种气味表示获得奖励的机会分别为50%,10%和90%。)
多巴胺细胞改变发射速率以指示预测误差,这意味着当收到的奖励恰好是细胞预测的确切大小时,预测误差应该为零。考虑到这一点,研究人员确定了每个细胞的反转点-多巴胺细胞不会改变其发射速率的奖励大小-并比较了它们是否存在差异。
他们发现,某些单元格预测了大量的奖励,而另一些单元格则预测了很少的奖励,远远超出了可变性可能带来的差异。他们在测量了不同细胞展现出阳性预期和阴性预期的扩增程度之后,再次看到了多样性。他们观察到,放大其阳性预测误差的相同细胞具有更高的逆转点,表明它们已被调整以期望更高的奖励量。
在最后的实验中,研究人员试图从多巴胺细胞的发射速率中解码奖励分布。他们报告了成功:通过推理,他们设法重建了与老鼠从事的任务中的实际奖励分配相匹配的分配。
“在研究来自AI的思想的过程中,很容易将注意力集中在从AI到神经科学的思想流中。但是,我们认为结果对于AI同样重要。” DeepMind神经科学研究主任Matt Botvinick说。“当我们能够证明大脑采用了我们在AI工作中所使用的算法时,就增强了我们的信心,即这些算法从长远来看将是有用的-它们可以很好地扩展到复杂的现实世界中,与其他计算过程的接口很好。其中涉及一种验证:如果大脑正在做,那可能是个好主意。”
蛋白质折叠
两篇论文的第二篇详细介绍了DeepMind在蛋白质折叠领域的工作,这项工作始于两年前。正如研究人员所指出的那样,预测蛋白质形状的能力是了解蛋白质如何在体内发挥作用的基础。这不仅对健康有影响,而且可以帮助应对许多社会挑战,例如管理污染物和减少废物。
蛋白质的配方(由氨基酸组成的大分子组成,氨基酸是组织,肌肉,头发,酶,抗体和其他生物的基本组成部分的基本组成部分)在DNA中编码。这些遗传定义界定了它们的三维结构,从而决定了它们的功能。例如,抗体蛋白质的形状像“ Y”形,使它们能够锁定在病毒和细菌上,而胶原蛋白的形状像绳索,在软骨,骨骼,皮肤和韧带之间传递张力。
但是众所周知,很难在几毫秒内发生蛋白质折叠。DNA仅包含有关氨基酸残基链的信息,而不包含那些链的最终形式。实际上,科学家估计,由于氨基酸之间相互作用的数量无法估量,要找出典型蛋白质的所有可能构型,然后再确定正确的结构,就需要花费超过138亿年的时间(这种现象被称为列文塔尔悖论)。 。
因此,DeepMind团队率先采用了名为AlphaFold的机器学习系统,而不是依靠常规方法来预测蛋白质结构,例如X射线晶体学,核磁共振和低温电子显微镜。它可以预测每对氨基酸之间的距离以及连接的化学键之间的扭转角,将其合并为一个分数。单独的优化步骤通过梯度下降(一种改进结构以更好地与预测匹配的数学方法)细化分数,使用所有距离的总和来估计拟议结构与正确答案的接近程度。
迄今为止,最成功的蛋白质折叠预测方法已经利用了所谓的片段装配,即通过采样过程创建结构,从而最大程度地减少了来自蛋白质数据库中结构的统计潜力。(顾名思义,蛋白质数据库是有关蛋白质,核酸和其他复杂装配体的3D结构信息的开源存储库。)在片段装配中,通常通过更改结构的形状来反复修改结构假设。一段较短的时间,同时保留降低电位的变化,最终导致电位低的结构。
借助AlphaFold,DeepMind的研究团队专注于从头开始为目标形状建模而无需以已解决的蛋白质为模板的问题。他们使用上述评分功能,搜索了蛋白质结构,找到了符合其预测的结构,并用新的蛋白质片段替换了蛋白质结构的片段。他们还训练了一个生成系统来发明新片段,并与梯度下降优化一起使用以改善结构得分。
该模型对从31,247个域中从蛋白质数据库中提取的结构进行了训练,这些结构被分为分别包含29,427和1,820个蛋白质的训练集和测试集。(本文中的结果反映了包含377个域的测试子集。)培训被划分为八张图形卡,大约花了五天的时间才能完成600,000个步骤。
经过全面训练的网络可以预测每对氨基酸与其作为输入基因序列的距离。具有900个氨基酸的序列可翻译为约40万个预测。
自1994年以来,AlphaFold参加了2018年12月的蛋白质结构预测关键评估比赛(CASP13),该竞赛每两年举行一次,为团体提供了测试和验证其蛋白质折叠方法的机会。对通过实验已经解决但其结构尚未公开的蛋白质结构进行预测评估,证明了方法是否可以推广到新蛋白质。
AlphaFold通过预测43种蛋白质中24种蛋白质的最准确结构赢得了2018年CASP13。DeepMind贡献了五种材料,这些材料是从系统的三种不同变体产生的八种结构中选择的,所有这些结构均使用了基于AI模型距离预测的电位,其中一些结构是由梯度下降系统生成的。DeepMind报告说,AlphaFold在免费建模类别中表现特别出色,可以在没有类似模板的情况下创建模型。实际上,它在该类别中获得了52.8的z分数总和(衡量系统相对于平均水平的性能),领先于次佳模型的36.6。
UCL生物信息学小组负责人David Jones写道:“蛋白质的3D结构可能是科学家可以获得的最有用的信息,以帮助了解蛋白质的作用及其在细胞中的工作方式。”项目的一部分。“确定蛋白质结构的实验技术既费时又昂贵,因此迫切需要更好的计算机算法来直接从编码蛋白质的基因序列中计算蛋白质的结构,而DeepMind致力于将AI应用到这个长期存在的问题上在分子生物学中是绝对的进步。最终目标是确定每种人类蛋白质的准确结构,这最终可能会导致分子医学的新发现。”