在计算神经网络时,常规的计算机芯片已达到极限。由NVIDIA和Google等公司开发的图形处理器和用于AI的特殊硬件功能更为强大。神经形态芯片基本上类似于真实的神经元,并且工作效率很高。量子计算机还可以极大地提高计算能力。

没有人工智能,就不可能实现自动驾驶和自动驾驶功能。所需的计算能力由专门从事并行计算的专用芯片提供。但是研究人员也在研究新的,受生物学启发的解决方案,以及在有望实现更大计算能力的量子计算机上。
几十年来,电子技术在汽车中变得越来越普遍。如今,数十种联网控制设备控制引擎,变速器,信息娱乐系统和许多其他功能。汽车早已成为滚动式计算中心,但如今,计算机功能的新飞跃正在等待着他们,因为自动驾驶功能和自动驾驶需要越来越强大的计算机。而且由于传统的芯片无法实现所需的性能,因此图形处理器,张量处理单元(TPU)和其他专门为计算神经网络而设计的硬件的时机已到。
尽管常规的CPU(中央处理单元)可以普遍使用,但它们缺乏用于AI的最佳架构。这是由于在神经网络的训练和推理过程中发生的典型计算。“神经网络中的矩阵乘法非常复杂,”卡尔斯鲁厄技术学院(KIT)Steinbuch计算中心的MarkusGötz博士解释说。“但是这些计算非常适合并行化,尤其是图形卡。具有24个内核和矢量命令的高端CPU可以每个周期执行24次4计算。配备现代图形卡的显卡已超过5,000个。”

图形处理器(GPU,图形处理单元)从一开始就专为并行工作而设计,并为此目的量身定制了内部架构:GPU包含成百上千个用于整数和浮点运算的简单计算模块,这些模块可以同时应用相同的功能对不同数据进行操作(单指令多个数据)。因此,它们能够在每个时钟周期执行数千个计算操作-例如,计算虚拟景观的像素或神经网络的矩阵乘法。因此,毫无疑问,GPU制造商NVIDIA的芯片目前处于理想的位置,成为一般和特别是自动驾驶中人工智能的主力军。大众汽车使用美国公司的硬件。保时捷工程技术软件开发高级经理Ralf Bauer说:“自动驾驶需要特殊的硬件。” “ GPU是起点;稍后,可能会推出专用芯片。”
NVIDIA当前提供专门用于自动驾驶的Xavier流程。一个硅芯片配备了八个常规CPU和一个专门针对机器学习而优化的GPU。对于2级以上的自动驾驶(有限的纵向和横向控制以及与2级相比,基于标准传感器的增强功能),可以使用Drive AGX Xavier平台,该平台每秒最多可以执行30万亿次计算操作(30 TOPS,每秒Tera操作数)。对于高度自动化和自动驾驶,NVIDIA拥有Drive AGX飞马(320 TOPS),在没有人为干预的情况下,测试车可以行驶至80公里,而无需经过硅谷。作为Xavier的继任者,NVIDIA目前正在开发Orin GPU,尽管目前对其性能数据知之甚少。
并非所有汽车制造商都使用GPU。2016年,特斯拉开始开发自己的神经网络处理器。这家美国公司自2019年初开始在其车辆中安装FSD(全自动驾驶)芯片,而不是NVIDIA的图形处理器。除了两个神经处理单元(NPU)(每个单元72个TOPS)之外,它还包含十二个用于常规计算的常规CPU内核和用于图像和视频数据的后处理的GPU。像GPU这样的NPU都是并行专用的,因此可以快速执行加法和乘法运算。
适用于AI应用的Google芯片
谷歌是芯片业务的又一新兴市场:自2015年以来,这家技术公司一直在其数据中心中使用自主开发的TPU。该名称来自数学术语“张量”,其中包括向量和矩阵以及其他元素。这就是Google广泛使用的人工智能软件库称为TensorFlow的原因,并且为此芯片进行了优化。Google在2018年推出了第三代TPU,其中包含四个“矩阵乘法单元”,据说可以实现90 TFLOPS(每秒的每秒浮点运算)。Google的子公司Waymo使用TPU训练神经网络进行自动驾驶。
诸如Tesla的FSD或Google的TPU之类的专用芯片只有大量使用时才变得经济。一种替代方法是FPGA(现场可编程门阵列)。这些通用的数字芯片包含无数的计算和存储块,可以通过编程将它们相互组合在一起,并可以将算法实质上注入到硬件中(例如使用专用芯片,但价格便宜得多)。FPGA可以轻松地适应AI应用程序的特定要求(例如指定的数据类型),从而在性能和能耗方面产生好处。总部位于慕尼黑的初创公司Kortiq已开发出用于FPGA的AIScale架构,
一些研究人员正在寻求与AI专用芯片的神经细胞功能更加紧密的联系。海德堡大学的研究人员开发了神经形态系统BrainScaleS,其人工神经元被实现为硅芯片上的模拟开关:细胞体由大约1,000个晶体管和两个电容器组成,突触大约需要150个晶体管。可以将单个细胞体作为模块组合以形成各种类型的人工神经元。这些突触可以像自然界中那样形成牢固的连接,并且还具有兴奋性和抑制性类型。神经元的输出由“尖峰”组成,持续数微秒的短电压脉冲充当其他人工神经元的输入。
能神经芯片
但是BrainScaleS不仅用于研究人脑。技术神经元还可以用于解决技术问题,例如自动驾驶的目标检测。一方面,它们提供了约200万个神经元的每个模块约1万亿次运算操作(1,000 TOPS)的高计算能力。另一方面,模拟解决方案也消耗很少的能量。“例如,在数字电路中,每次操作使用大约10,000个晶体管,”海德堡大学的Johannes Schemmel解释说。“我们的耗电量大大减少,这使我们能够达到每瓦约100 TOPS。” 研究人员刚刚开发了第二代电路,并正在与行业合作伙伴讨论可能的合作。
来自云的量子能量
将来,甚至量子计算机也可以用于AI领域。它们的基本单位不是二进制位,而是具有无限数量可能值的qubit。借助量子力学定律,可以使计算高度并行化,从而加速计算。同时,由于量子位由诸如电子,光子和离子之类的敏感物理系统表示,因此量子计算机很难实现。例如,IBM Q System One演示了这一点,该公司在拉斯维加斯举行的CES 2019电子贸易展上推出了IBM Q System One。量子计算机的内部必须严格屏蔽振动,电场和温度波动。
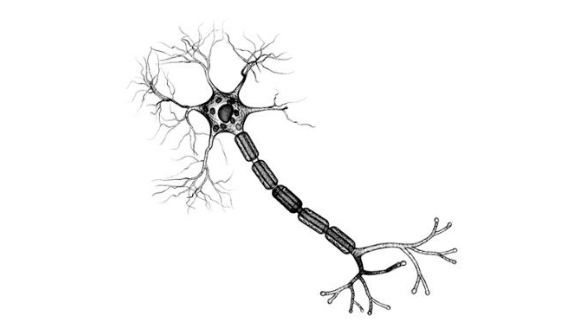
神经细胞和人工神经元
神经细胞 通过突触接收其他神经元发出的信号,这些突触位于树突上或直接位于细胞体上。突触可具有兴奋作用或抑制作用。所有输入都在轴突岗进行汇总,如果在此过程中超过阈值,则神经细胞会发出一个大约毫秒级的信号,该信号沿着轴突传播并到达其他神经元。
人工神经元 或多或少准确地模仿了这种行为。在具有多层的传统神经网络中,每个“神经细胞”都接收加权和作为输入。它由前一层神经元的输出和加权因子w i组成,其中存储了神经网络的学习经验。这些加权因子对应于突触,也可以是兴奋性的或抑制性的。像神经细胞一样,可配置的阈值确定何时人工神经元触发。
从神经网络学习和推理
自然和人工神经网络从突触连接强度和加权因子的变化中学习。在深度神经网络中,在训练过程中,将数据馈送到输入和输出,并与所需结果进行比较。使用数学方法, 不断调整加权系数w ij,直到神经网络可以可靠地放置图像(例如指定类别)。通过推论,例如,数据被馈送到输入,而输出则被用于决策。
在深度神经网络(具有多层人工神经元的网络)的训练和推理中,相同的数学运算会重复发生。如果将第1层神经元的输出和第2层神经元的输入都作为列向量相加,则所有计算都可以表示为矩阵乘法。在此过程中,发生了许多相互独立的乘法和加法,这些运算可以并行执行。常规CPU并非为此目的而设计的-这就是图形处理器,TPU和其他AI加速器在很大程度上优于它们的原因。